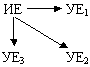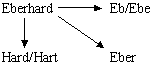| Языки | Общее количество исходных мужских имен (ИЕ) | Общее количество мужских имен (УЕ) |
|---|---|---|
| Dt. | 153 | 222 |
| Lat. | 144 | 121 |
| Gr. | 61 | 55 |
| Hebr. | 27 | 17 |
| Span.-ital. | 32 | 35 |
| Engl. | 30 | 59 |
| Slaw. | 16 | 35 |
| Fries. | 12 | 16 |
| Kelt. | 8 | 4 |
| Nederl.-skand. | 6 | 9 |
| Frz. | 5 | 12 |
| Итого: | 494 | 585 |
Как видно из таблицы, в процессе усечения участвуют 494 личных имени. Из них на долю немецких имен, если брать каждый язык в отдельности, приходится наибольшее количество единиц (153 ИЕ).
Достаточно высокую степень активности в процессе усечения проявляют греко-латинские имена. Группу заимствований из латинского образуют 144 опорные единицы, из греческого 61.
Степень активности базисных единиц из древнееврейского языка гораздо ниже по сравнению с греко-латинскими. По данным нашей выборки, их количество составляет 27 единиц. Количественная представленность испано-итальянских и английских имен приблизительно одинакова (32 и 30 единицы соответственно), что дает основание усматривать в этом одинаковую степень их активности в образовании дериватов. Участие в процессе усечения этих заимствованных имен изначально незначительно по сравнению с греко-латинскими именами и достаточно регулярно по сравнению с производством кратких единиц на базе заимствований из языков скандинавской группы, включая нидерландский, и французского языка. Но при этом следует отметить высокую репрезентативность славянских, фризских и кельтских имен.
Как показывают цифровые данные, зафиксированные в таблице 1, количественный состав УЕ и ИЕ не совпадает. Цифровое несовпадение УЕ и ИЕ (здесь и далее) объясняется многократностью усечения личных имен. В отличие от апелятивной лексики, подвергающейся одноразовому отсечению начальных и/или конечных формантов в базисных единицах, антропонимы участвуют в производстве одно-, двухступенчатых и объемных дериватов (см. об этом подробнее в §3 п. 3.3.).
Цифровые расхождения, касающиеся этимологической характеристики производных и производящих антропонимов процесса усечения, обусловлены тем, что создание немецких, английских и славянских УЕ осуществляется в основном на базе латинских и греческих имен.
Согласно приведенным в таблице 1 данным, количество немецких УЕ по уровню с исходными значительно возросло (153 ИЕ > 222 УЕ), а английских и славянских, увеличилось почти в 2 раза (59 и 35 УЕ соответственно).
Изменения в сторону уменьшения УЕ по отношению к ИЕ обнаруживается в латинской группе имен (144 ИЕ > 121 УЕ). Значительно сократилось число греческих, еврейских и кельтских имен (55, 17 и 4 УЕ соответственно).
Расхождение этимологической характеристики производных и производящих единиц процесса усечения можно отчасти объяснить тем, что на базе латинских, греческих и еврейских имен происходило образование немецких, английских и славянских УЕ, то есть в языках - рецепторах на базе более ранних заимствований.
Говоря о немецких мужских именах, не следует забывать о раздробленности Германии, царившей в ней на протяжении ряда веков. Этот факт дает основание предположить наличие диалектической разветвленности в составе немецких личных имен.
Наблюдения над анализируемым языковым материалом служат подтверждением данного предположения. В результате обобщения этого материала был выявлен территориально-диалектный состав коррелирующих единиц процесса усечения (см. таблицу 2).
Таблица 2
Диалектно-территориальный состав немецких личных мужских имен
| Диалекты | ИЕ | УЕ |
|---|---|---|
| Norddt. | 17 | 22 |
| Suddt. | 4 | 17 |
| Rhein. | 1 | 3 |
| Westdt. | 1 | 4 |
| Bayer. | - | 4 |
| Schweiz. | 1 | 9 |
| Итого: | 24 | 59 |
Исходя из данных таблицы 2, общее количество ИЕ составляет 24 имени, на базе которых создано 59 УЕ. В диалектном составе отмеченных в таблице ИЕ наибольшей распространенностью характеризуются имена, принадлежащие к северо-немецкому диалекту (17 ИЕ). Опорные мужские имена, имеющие иную диалектную закрепленность (южно-немецкие, западно-немецкие и т.д., см. таблицу) единичны. Среди УЕ превалируют имена не только северо-немецкого, но южно-немецкого диалектов (22 и 17 УЕ соответственно).
Специфической особенностью усеченных форм является наличие среди них дериватов, созданных в рамках одного из литературных вариантов немецкого языка, а именно, швейцарского, хотя их общее количество (9 УЕ) незначительно по сравнению с краткими формами, возникшими на базе северо- и южно-немецких диалектов.
В качестве производящей базы диалектальных усеченний могли использоваться как немецкие [Rudolf (dt.) > Rudo (bes) suddt.) Arnold (dt.) > Noll (rhein.)], так и заимствованные [Xaverus. (span..) > Ver (suddt., bayr.); Thomas (hebr.) > Thoma (oberdt.)] мужские имена. Среди заимствованных мужских имен обращают на себя внимание в основном единицы греко-латинского происхождения, что, несомненно, связано с ранним периодом их проникновения в немецкий язык и их широкого в нем использования.
В результате рассмотрения немецких и заимствованных производящих и производных единиц по языкам в отдельности четко вырисовывается максимальная (для немецких, латинских, греческих имен), средняя (для испано-итальянских, английских, еврейских, славянских имен) и минимальная (для французских, кельтских, фризских имен и имен нидерландо-скандинавской группы) продуктивность в создании производных. Вместе с тем, при совокупном рассмотрении СИ по группам "немецкие - заимствованные" мужские имена, общая картина резко меняется. Исконно немецких мужских имен, как исходных, так и усеченных, оказывается почти в два раза меньше заимствованных (153 ИЕ немецкого и 341 ИЕ иноязычного происхождения). Значительный удельный вес заимствованных антропонимов в рамках анализируемого материала объясняется целым рядом факторов социального и лингвистического порядка, которые в данной работе и не рассматриваются.
§2. Фонетические особенности исходных и усеченных единиц
| УЕ 2 слога | УЕ 3 слога | УЕ 4 слога | УЕ 5 слогов | УЕ 6 слогов | Всего УЕ | |
|---|---|---|---|---|---|---|
| ИЕ 1 слог | 137 | 54 | 17 | 4 | - | 212 |
| ИЕ 2 слога | 42 | 160 | 73 | 13 | - | 288 |
| ИЕ 3 слога | - | 4 | 55 | 18 | 1 | 77 |
| ИЕ 4 слога | - | - | 1 | 5 | 1 | 7 |
| ИЕ 5 слогов | - | - | - | - | 1 | 1 |
| Всего ИЕ | 163 | 184 | 115 | 29 | 3 | 494\585 |
С учетом проанализированного материала следует отметить, что наибольшее количество ИЕ приходиться на долю трехслоговых имен, таких как, например, Borislaw, Kilian и др. (всего 184 ИЕ). Высокую активность проявляют также двух- и четырехслоговые ИЕ (163 и 115 ИЕ соответственно) типа Leven, Siegmar, Polykarpus, Aldobrandus. Число пятислоговых ИЕ незначительно (29 ИЕ), например: Bonaventura, Eliodoro.
Согласно данным, приведенным в работе В. Зайбике, большинство личных имен в немецком языке являются двух- и трехслоговыми образованиями, что в равной мере характерно как для мужских, так и для женских имен данного языка. Слоговая характеристика мужских имен выглядит в частности в исследовании В Зайбике (W. Seibike, S. 104-105) следующим образом:
- однослоговые 17%
- двухслоговые 37%
- трехслоговые 38%
- четырехслоговые 7%
- пятислоговые 1%
Как видно из приведенных выше данных, мужские трех- и двуслоговые имена образуют в общей сложности 75% всего антропонимикона рассматриваемого разряда имен в немецком языке. При этом процентное соотношение двух- и трехслоговых имен приблизительно одинаково. Далее следуют однослоговые мужские имена. Количество же четырех- и в особенности пятислоговых имен незначительно. Большая распространенность трех - и двуслоговых фонетических структур в именном фонде немецкого языка создает благоприятную почву для вовлечения их в процесс усечения. Достаточно активное участие четырехслоговых опорных мужских имен в процессе усечения обусловлено, на наш взгляд, самой структурой этих единиц, позволяющей ее сокращать.
В рамках результата процесса усечения первое место по количественному составу занимают двуслоговые имена (288 УЕ): Frido < Fridolin. Далее следуют однослоговые (212 УЕ) типа Renz < Laurenz и трехслоговые усечения (77 УЕ). См., например, Valentin < Valentinus. Четырех- и пятислоговые усеченные имена, такие как Aurelian < Aurelianus, Augustin < Augustinus, малочисленны.
Образование двухслоговых усечений связано, по всей видимости, с общей тенденцией существования в сфере мужских имен двухслоговых фонетических структур, доминирование однослоговых УЕ объясняется высокой активностью двухслоговых ИЕ в анализируемом процессе, на базе которых образуются в основном однослоговые УЕ. По данным количественного подсчета, от 163 двухслоговых ИЕ возникло 137 однослоговых УЕ. Например: Tühnes > Tün, Wolfbert > Bert. Трехслоговые ИЕ служат основой для создания двухслоговых имен (160 УЕ), таких как Dragomar > Drago, Pascalis > Pascal. Четырехслоговые имена являются источником возникновения как двух-, так и трехслоговых имен (73 и 55 УЕ соответственно): Remigius > Remi. Такая приблизительно в равной пропорции картина наблюдается и относительно пятислоговых ИЕ, на базе которых создаются преимущественно двух- и трехслоговые усечения (13 и 18 УЕ соответственно) типа: Laurentius > Laurenz, Theodebaldus > Baldus.
Заслуживает внимание и то, что этимологическая характеристика мужских имен, участвующих в процессе усечения на формирование слоговой структуры результата данного процесса в целом не влияет, хотя некоторые закономерности здесь все же прослеживаются. Так, например, наибольшую активность в образовании двуслоговых имен проявляют трех- и четырехслоговые немецкие и латинские имена. В образовании же однослоговых усечений наибольшее участие принимают двухслоговые немецкие и английские имена. Появление однослоговых УЕ на базе английских мужских имен соответствует положению, высказанному в работе М. Сегаля применительно к нарицательным именам. Из него вытекает, что различные фонетические процессы, происходившие в различные периоды истории английского языка, способствовали тому, что однослоговые слова стали иметь большой удельный вес в современном английском языке. Это привело к тому, что однослоговые слова стали восприниматься в нем как некая норма, как своеобразная структурная модель (М. Сегаль, с. 17).
| ИЕ Хх | ИЕ Ххх | ИЕ хХх | ИЕ ххХ | ИЕ Хххх | ИЕ хХхх | ИЕ ххХх | ИЕ хххХ | ИЕ хХххх | ИЕ ххХхх | ИЕ хххХх | Итого УЕ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| УЕ Х | 137 | 37 | 14 | 3 | 5 | 4 | 3 | 203 | ||||
| УЕ Хх | 42 | 82 | 43 | 4 | 7 | 24 | 19 | 2 | 5 | 8 | 236 | |
| УЕ хХ | 4 | 27 | 1 | 18 | 2 | 52 | ||||||
| УЕ Ххх | 1 | 3 | 12 | 17 | 3 | 2 | 5 | 43 | ||||
| УЕ хХх | 1 | 7 | 8 | |||||||||
| УЕ ххХ | 2 | 3 | 20 | 7 | 32 | |||||||
| УЕ Хххх | 2 | 2 | ||||||||||
| УЕ хХхх | 2 | 2 | 4 | |||||||||
| УЕ ххХх | 3 | 3 | ||||||||||
| УЕ хххХ | 2 | 2 | ||||||||||
| Итого ИЕ | 163 | 107 | 70 | 7 | 10 | 55 | 49 | 1 | 1 | 17 | 11 | 491\582 |
Из вышеприведенной таблицы следует, что среди двухслоговых исходных мужских имен преобладает тип ударения Хх - ударение на первый слог 163 ИЕ: Thomas, Stefan; в трехслоговых именах возможны три типа ударения Ххх (Eduard, Michael), xXx (Mathias, Roberto) и xxX (Theophan, Nikola), при явном преобладании первого из них. Общее количество имен с ударением на первом слоге составляют 107 ИЕ. Широко представлен здесь и второй тип ударения хХх - 70 ИЕ. Мужские исходные имена с акцентной структурой ххХ единичны (7ИЕ). Четырехслоговые имена оформалены в основном по следующим акцентным моделям хХхх (Hippolytos, Cölestinus - 55 ИЕ) и ххХх (Antoninus, Severinus - 49 ИЕ).
Среди пятислоговых мужских имен более менее частотны следующие типы ударения: ххХхх (Jnnocentius, Gaudentius - всего 17 ИЕ) и xxxXx (Bartholomäus, Theodebaldus - 11 ИЕ). Остальные типы ударения представляют собой скорее исключение, чем правило.
Акцентная характеристика УЕ может быть представлена тремя группами. В первую входят два самых распространенных типа ударения Xx (Chrispin<Chrispinus, Remy<Remigius - 236 УЕ) и Х (Jan<Jannis, Fred<Fredegar - 203 УЕ). Вторая группа характризутся средней степенью распространенности, к ней относятся следующие типы ударения: хХ (Pascal<Paskalis, Vigil<Virgilius - 52 УЕ), Ххх (Jnnozenz<Jnnoсentius, Agilu<Agilus - 43 УЕ) и ххХ (Eustach<Eustachius, Hippolyt<Hippolytus - 32 УE). В третью группу входят все остальные типы ударений. В силу пестроты картины указанных акцентных свойств усечений и их единичности далее в тексте они не рассматриваются.
Описанные выше акцентные структуры полных и кратких форм мужских имен не дают, однако, представления о наличии каких-либо закономерностей, свидетельствующих о вычлени ударных компонентов в производящих единицах. В связи с этим представляется далее необходимым провести количественный подсчет вторичных единиц, сохраняющих в своей структуре ударный слог первичных.
По данным подсчета, состав усеченных имен сохранивших ударный компонент прототипа образуют 437 УЕ, не сохранивших - 112 УЕ.
Сохранение ударных слогов в производных структурах свидетельствует в определенной мере о предсказуемости их образования.
§3. Словообразовательная структура опорных и усеченных имен
| ИЕУЕ | Модели двухосновных имен | ВсегоУЕ | L1+L2 | l1+L2 | L1+l2 |
|---|---|---|---|---|---|
| 1 | L1 | 115 | 18 | 7 | 140 |
| 2 | L2 | 23 | 20 | - | 43 |
| 3 | L1+l2R | 21 | - | 1 | 22 |
| 4 | l1R | 8 | 7 | - | 15 |
| 5 | Rl1+L2 | 6 | 5 | - | 11 |
| 6 | l1 | 5 | - | 1 | 6 |
| 7 | l1+l2R | - | 19 | - | 19 |
| 8 | Rl1+l2R | 2 | - | - | 2 |
| всего | УЕ | 180 | 69 | 9 | 258 | ИЕ | 158 | 50 | 8 | 216 |
Как видно из данных таблицы, полноосновные так же, как и сложносокращенные антропонимы тяготеют к вычленению в их составе оного компонента ИЕ. См. модели L1, L2 в таблице 5. По моделям L1, L2 было образовано в общей сложности 138 полноосновных и 38 сложносокращенных УЕ.
Следует также отметить активность сложносокращенных имен в образовании усечений по модели L1+l2R - 19 УЕ.
Как и полноосновные сложные имена, сложносокращенные не отличаются особой актвностью в порождении двухкомпозитных структур. Вторичные квазисложные имена со структурами Rl1+L2R, Rl1+l2R зафиксированы в мужском именнике в количестве 8 УЕ среди полноосновных, сложносокращенные имена менее активны они образуют 5 УЕ.
Согласно приведенным данным в усечении мужских двухосновных имен наиболее распространены следующие модели УЕ: L1 (140 УЕ), L2 (43 УЕ), L1+l2R (22УЕ). Репрезентативность остальных же структур незначительна.
3.3. Ступенчатая и объемная антропонимическая деривация.
При сопоставлении опорных и усеченных имен было установлено, что число производящих и производных единиц не совпадает. Это объясняется тем, что на базе одного и того же имени возможно образование нескольких усечений по принципу объемности и ступенчатости. Образование вторичных единиц осуществляется при ступенчатой деривации по формуле ИЕ>УЕ1>УЕ2 - Maximilian>Maxim>Max.
Формула объемной деривации может быть представлена в следующем имени:
Иллюстрацией объемного усечения может служить следующий пример:
Возникновение нескольких вторичных единиц на базе одной и той же первичной, позволяет говорить о действии в сфере производства усеченных мужских имен помимо одноразового или одноступенчатого сокращения прототипов, ступенчатого или объемного их усечения. Наличие ступеней деривации может создать впечатление об отсутствии каких либо правил, регулирующих образование антропонимических кратких форм. Ближайшее рассмотрение усеченных имен, их сопоставление с исходными, однако, показывает, что определенная степень предсказуемости все же существует. Заслуживает внимания прежде всего тот факт, что большинство антропонимов (422 из 494 УЕ) подвергаются одноразовому усечению. Возможность формирования кратких имен по принципу "объемности" и особенно "ступенчатости" сведена до минимума. В объемной деривации участвуют 49 ИЕ, образующие в процессе усечения 110 УЕ. В списке зафиксированных нами имен, допускающих образование "ступенчатых усечений" значится 23 ИЕ, служащие для образования 53 УЕ.
Кроме минимальной продуктивности ступенчатого усечения в пополнении состава кратких имен, оно характеризуется тем, что радиус его действия ограничен зоной мужских имен, оканчивающихся в подавляющем своем большинстве на -ius, -us, -ios, -os (17 из 23 ИЕ) имеют эти форматы. Название форманты свидетельствует о том, что в "ступенчатой" деривации участвуют в подавляющем большинстве случаев греко-латинские имена.
Немаловажно и то, что в рамках указанной группы мужских имен возможна только ступенчатая деривация. Образование вторичных единиц осуществляется по формуле (см. с.?? ).
Результатом двухступенчатой деривации является инициальные антропонимы (19 из 23 ИЕ). В исходных или первичных сокращенных единицах (УЕ1) устраняются конечные сегменты.
По сравнению с двухступенчатым усечением объемное играет более заметную роль в пополнении немецкого антропонимикона мужскими именами, что в первую очередь определяется достаточно активным в нем участием производящих единиц, а также характером образования производных. Деривационной базой для создания рассматриваемой группы служат, как отмечено выше, 49 прототипов, на основе которых возможно появление серии кратких форм.
Характерной группой образования дериватов по принципу объемности является отсечение в исходном имени его начальной или конечной части: Joachim>Jo, Achim; Eberhard>Eb/Ebe, Hard/Hart. Возникающий вследствие такого сокращения объемный деривационный ряд репрезентируется обычно двумя, как правило, инициально-финальными сокращениями.
Не исключена представленность объемного ряда двумя инициально-финальными (Alex, Xander<Alexander), медиально-финальными (Basti, Bastian<Sebastian) и финальными (Dolf, Olf<Adolf) усечениями с соответствующим названному вычленением части исходной единицы. Однако такие ряды, хотя и образуются, но довольно редко.
Редкостью при объемной деривации антропонимов является серийное производство кратких имен типа Bonifaz, Fazius, Azius<Bonifacius. Оно прослеживается в 5 из 49 случаев сокращения производящих единиц.
Одно-, двухступенчатое и объемное сокращение антропонимов обуславливают структурное и классификационное разнообразие имен вообще и вариативность форм одного имени в частности. Из-за создания различных ненормативных отклонений производство усеченных антропонимических единиц не отличается особой стабильностью.
Предпосылки варьирования собственных имен заложены, по справедливому замечанию А.В. Суперанской, в самом характере этих имен: более слабом, чем у нарицательных, "облике" морфем (А.В. Суперанская, с. 21). Исследуемый материал полностью подтверждает точку зрения лингвиста.
ГЛАВА III. ЛЕКСИКО-ГРАММАТИЧЕСКИЙ АСПЕКТ УСЕЧЕНИЯ ЛИЧНЫХ ИМЕН